Berücksichtigung von Drittvariablen
Neuronale Netze
neuronale Netze
Definition
Neuronale Netze stellen einen Oberbegriff dar, der zahlreiche, zum Teil sehr unterschiedliche Modelle umfasst. Selbst traditionelle statistische Verfahren wie die Regressionsanalyse lassen sich als Spezialfälle neuronaler Netze beschreiben. Gemeinsam ist all diesen Netzen aber, dass Matrizenberechnungen durchgeführt werden und dabei Informationen aufgenommen, verarbeitet und ausgegeben werden.
künstliche neuronale Netze
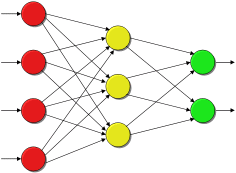
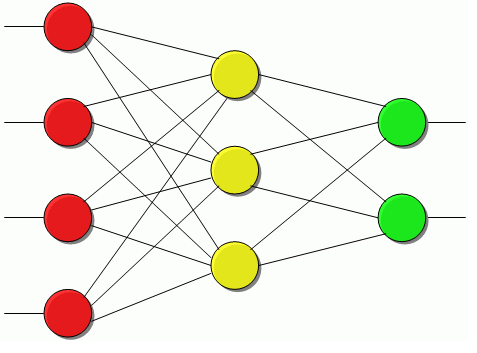
- Abbildung 24: Schematische Darstellung eines neuronalen Netzes.
Beispiel
Bezüglich der Informationsaufnahme würde man bei dem oben aufgeführten Beispiel Versuchsperson für Versuchsperson die Faktorstufen der unabhängigen Variablen (z.B. Null für Kontrollbedingung und Eins für Trainingsbedingung) sowie weitere Drittvariablen (z.B. die Intelligenz des jeweiligen Probanden) als Eingabewerte bereitstellen. Diese Informationen würden durch das Netz (Abb. 24) in mehreren Schritten verarbeitet und zugleich zu seiner Modifikation beitragen. Abschließend erfolgt die Informationsausgabe. So wird beispielsweise in Abhängigkeit der Versuchsbedingung (Trainings- oder Kontrollbedingung) und eines Intelligenzwertes die Lernleistung (abhängige Variable) vorhergesagt.
Weiterführende Informationen
Weiterführende Informationen zu neuronalen Netzen finden Sie auf meiner Webseite www.neuronalesnetz.de oder in dem dazugehörigen Lehrbuch (Rey & Wender, 2010).
Beispiel
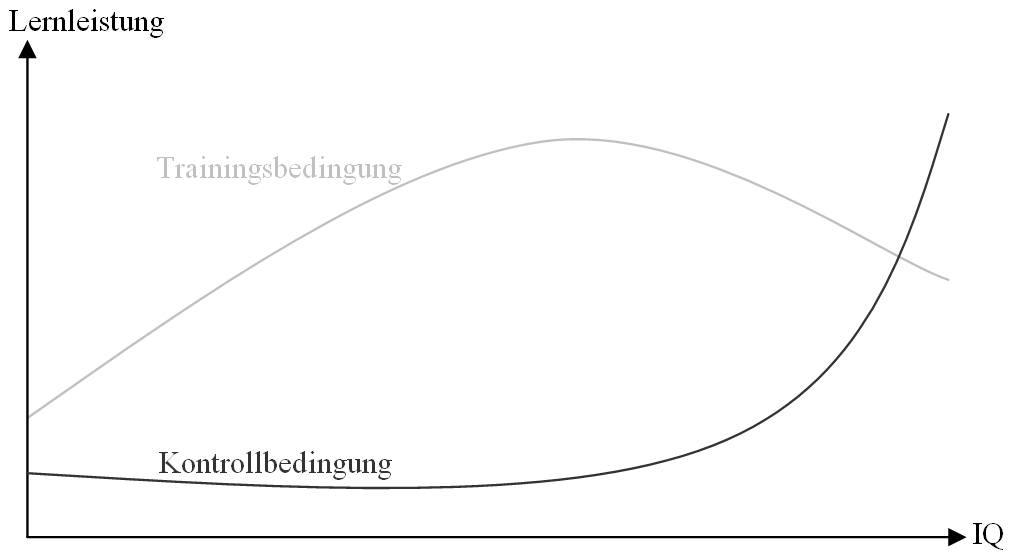
Abb. 25 visualisiert ein fiktives Beispiel zur Datenauswertung mittels neuronaler Netze. Hiernach würden Probanden mittlerer Intelligenz unter der Trainingsbedingung bessere Lernleistungen erzielen als niedrig- oder hochintelligente Versuchsteilnehmer. Denkbar wäre, dass die Trainingsbedingung für weniger intelligente Versuchspersonen zu schwer und für hochintelligente Lerner zu leicht ist. Unter der Kontrollbedingung hingegen zeigen die meisten Benutzer eine ähnliche Lernleistung. Erst bei hoher Intelligenz nimmt die Lernleistung mit steigender Intelligenz der Probanden rasch zu.
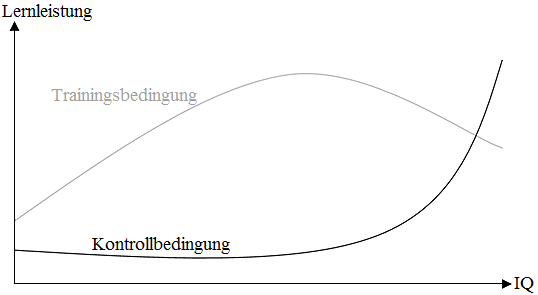
- Abbildung 25: Fiktiver, nonlinearer Zusammenhang zwischen Intelligenz, Versuchsbedingung (Trainingsbedingung versus Kontrollbedingung) und Lernleistung.
Vorteile
Innerhalb der psychologischen Forschung werden erhobene Daten mittels (künstlicher) neuronaler Netze derzeit nur sehr selten analysiert. Dabei weisen diese bei der Datenauswertung diverse Vorteile auf (z.B. Weber, 2001). So können sie beispielsweise komplexe, nonlineare Zusammenhänge im Datensatz aufdecken (Rey & Wender, 2010). Zwar können derartige Zusammenhänge ebenfalls mit Hilfe des Allgemeinen Linearen Modells (ALM) detektiert werden (z.B. Moosbrugger, 2002), jedoch ist dort die Vorgabe eines spezifischen Modellterms (z.B. x2) notwendig. Auch andere komplexe Zusammenhänge lassen sich mittels neuronaler Netze mitunter besser aufdecken als mit herkömmlichen statistischen Verfahren. Zu beachten ist dabei, dass sich diese traditionellen Verfahren mathematisch auch als Spezialfälle neuronaler Netze darstellen lassen und es sich somit beispielsweise bei der Regressionsanalyse ebenfalls um ein neuronales Netz handelt.
Allgemeines Lineares Modell
Nachteile
Nachteilig bei neuronalen Netzen im Rahmen der Datenauswertung sind die häufig schwierige Interpretation der komplexen, nonlinearen Zusammenhänge und die benötigte Expertise des "Netzwerkarchitekten". Zudem werden neuronale Netze nicht von allen Statistikprogrammen unterstützt. Außerdem ist die Gefahr des Overfittings der Daten besonders groß (Rey & Wender, 2010).
overfitting
Problem: Overfitting
Das Problem des Overfittings wird in der Literatur auch als capitalization on chance oder Bias-Varianz-Dilemma bezeichnet. Dieses Problem tritt auf, wenn zufällige Variationen im (Trainings-)Datensatz durch das Modell und deren unabhängige Variablen miterfasst werden. In diesem Fall prognostiziert das neuronale Netz zwar die Daten der ursprünglich untersuchten Stichprobe sehr gut, nicht aber die Messwerte einer neuen Stichprobe. Eine Verallgemeinerung des Modells auf die Grundgesamtheit ist folglich nicht statthaft (Rey & Wender, 2010). Dem Problem kann durch Replikation (Wiederholung) des Versuchs oder Kreuzvalidierung begegnet werden. Bei der Kreuzvalidierung wird die Stichprobe in zwei Untergruppen unterteilt:
Trainingsdatensatz
- Trainingsmenge: Diese Teilstichprobe dient zur Berechnung des (Vorhersage-) Modells. Beispielsweise könnten die erhobenen Intelligenzleistungen und andere Daten der Untersuchungsteilnehmer aus der Studie zur Berechnung des Modells herangezogen werden.
- Validierungsmenge: Diese Teilmenge wird nicht zur Berechnung, sondern ausschließlich zur Überprüfung des Modells herangezogen. Denkbar wäre die Prüfung des Modells an einer neuen, noch zu erhebenden Gruppe von Versuchspersonen.