Hypothesenüberprüfung
Grundlagen der Inferenzstatistik I
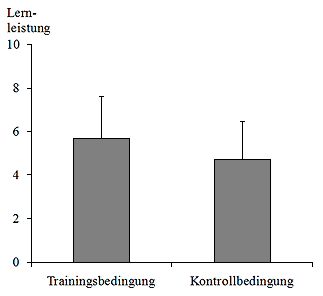
- Abbildung 26: Graphische Veranschaulichung der Mittelwerte und nach oben abgetragenen Fehlerindikatoren (Standardabweichungen) für die Trainings- und Kontrollbedingung.
Beispiel
Die Datenauswertung dient häufig zur Überprüfung von Hypothesen, die im Vorfeld einer Untersuchung aufzustellen sind. Beispielsweise könnte man die Hypothese H1 aufstellen, dass ein Trainingsprogramm zum Erwerb mathematischer Kompetenzen im Vergleich zu einer Kontrollgruppe ohne ein solches Trainingsprogramm zu einer Verbesserung der mathematischen Fähigkeiten führt. Dazu könnte man zunächst die Mittelwerte der Lernleistung beider Gruppen berechnen und diese in einem Diagramm abtragen (Abb. 27).
Zufallseinflüsse
Auch wenn die Mittelwerte, wie in Abb. 26 dargestellt, für die Hypothese H1 sprechen, ist es möglich, dass Zufallseinflüsse zu den besseren Leistungen in der Trainingsbedingung geführt haben. Zum Beispiel könnten trotz zufälliger Zuweisung der Versuchspersonen auf die beiden Bedingungen in die Trainingsgruppe vermehrt Personen enthalten sein, die vor Beginn der Untersuchung über höhere mathematische Kompetenzen verfügen. Um derartige Zufallseinflüsse mit möglichst hoher Wahrscheinlichkeit ausschließen zu können, bedient man sich der Inferenzstatistik.
Inferenzstatistik und Nullhypothese
In der Inferenzstatistik wird die Wahrscheinlichkeit ermittelt, dass die Muster, die bei der Datenauswertung in den Zahlen gefunden wurden, zufällig entstanden sind. Die dazugehörige Hypothese wird als Nullhypothese (H0) bezeichnet. Im oben aufgeführten Beispiel würde man der Nullhypothese zufolge annehmen, dass Lernleistungsunterschiede zwischen der Trainings- und Kontrollgruppe zufällig entstanden sind und nicht auf Einflüssen durch das Trainingsprogramm beruhen.
Zufallsstichproben
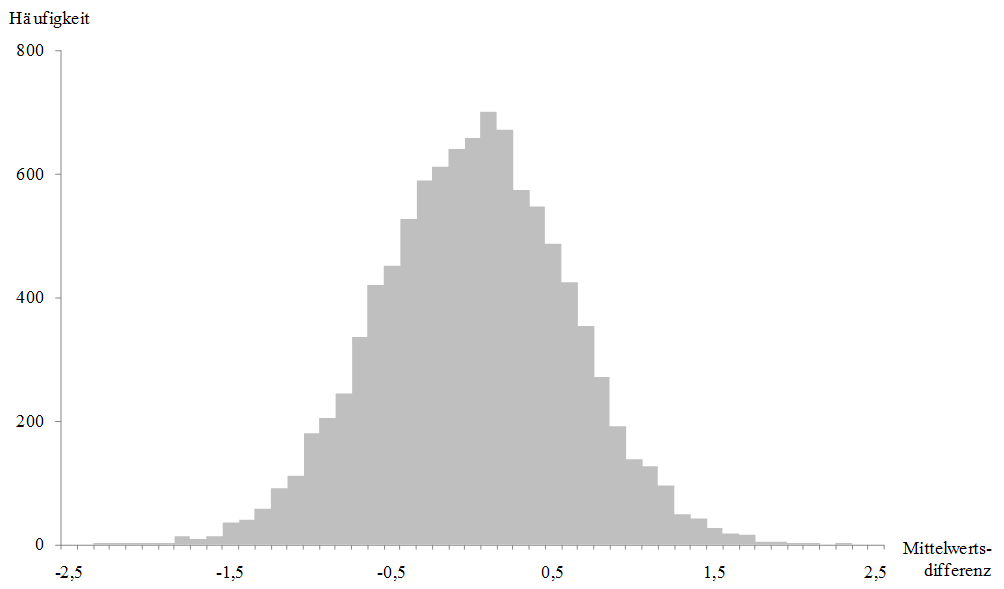
Um zu überprüfen, mit welcher Wahrscheinlichkeit ein Untersuchungsergebnis entsteht, wenn der Zufall regiert, könnte man zunächst zahlreiche Zufallsstichproben erzeugen und die Auftretenswahrscheinlichkeit für ein bestimmtes Muster ermitteln. Tritt das Muster in den Zufallsstichproben nur sehr selten auf, dann ist die Wahrscheinlichkeit gering, dass es zufällig zustande gekommen ist. Im Hinblick auf das Trainingsprogramm zum Erwerb mathematischer Kompetenzen könnte man beispielsweise zunächst je 10000 Zufallsstichproben für die Trainings- und für die Kontrollbedingung erzeugen. Die dazugehörigen Mittelwertsdifferenzen wurden in Abb. 27 abgetragen. Dabei wurden pro Stichprobe, ähnlich wie in der realen Stichprobe, für jede fiktive Versuchsperson zufällig Werte zwischen null und zehn generiert. Diese Zufallswerte waren nicht normalverteilt, sondern variierten gleichmäßig zwischen null und zehn. Erkennbar ist in Abb. 27, dass besonders niedrige und besonders hohe Mittelwertdifferenzen in Zufallszahlen nur sehr selten auftreten.
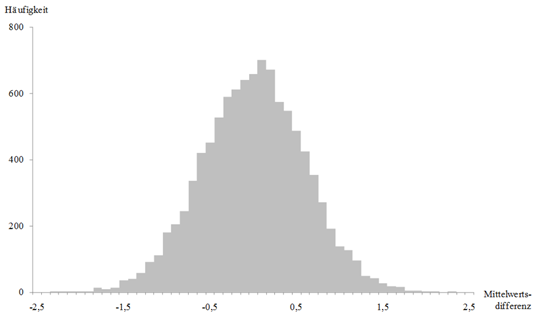
- Abbildung 27: Häufigkeitsdiagramm mit 10000 Zufallsstichproben, in dem die Mittelwertsdifferenzen zwischen zwei Gruppen mit 56 und 57 fiktiven Probanden abgetragen wurden.
t-Verteilung
t-Verteilung
- Video 3: t-Verteilung
In den Anfängen der Inferenzstatistik zu Beginn des 20. Jahrhunderts standen noch keine Computer zur Generierung von zahlreichen Zufallsstichproben zur Verfügung. Stattdessen wurden mathematische Funktionen entwickelt, welche in etwa der Häufigkeitsverteilung von Zufallsstichproben entsprechen. Zur Häufigkeitsverteilung der Abb. 27 hat William Sealey Gosset im Jahr 1908 eine Wahrscheinlichkeitsverteilung aufgestellt, die als t-Verteilung (auch Student-t-Verteilung) bezeichnet wird. In Abb. 28 wurde eine solche t-Verteilung abgetragen. Je nach Anzahl an Versuchspersonen resultieren t-Verteilungen, die sich untereinander unterscheiden. Gemeinsam ist diesen Verteilungen, dass sie etwas schmalgipfliger als Standardnormalverteilungen sind. Allerdings gehen t-Verteilungen bei einem Gesamtstichprobenumfang von über 50 Personen zunehmend in eine Standardnormalverteilung über.
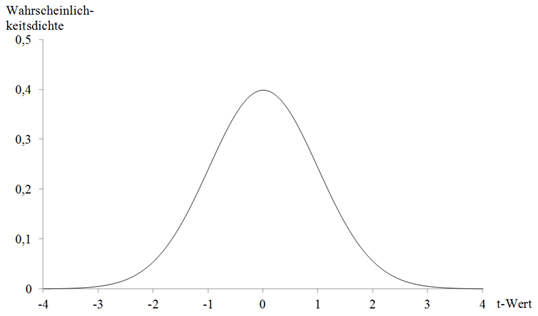
- Abbildung 28: t-Verteilung zu einer Stichprobe mit 113 Versuchspersonen (dadurch resultieren 111 Fehlerfreiheitsgrade).
Kritischen und empirischen t-Wert bestimmen
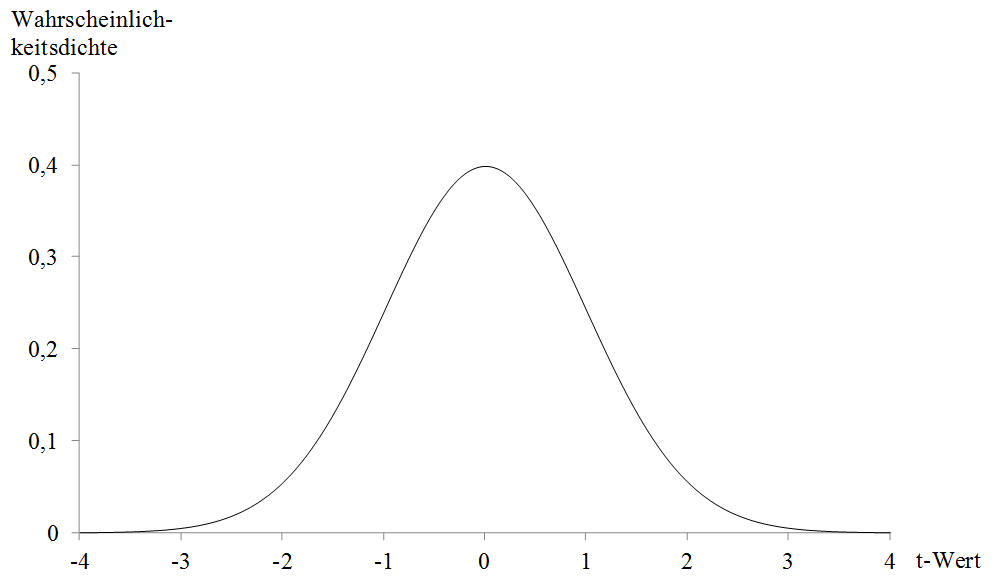
Nachdem man die t-Verteilung wie in Abb. 28 mittels einer Formel erzeugt hat, kann man verschiedene Flächenanteile unter der Kurve abtragen. In Abb. 29 wurde beispielsweise auf der rechten Seite ein Flächenanteil von 5% an der Gesamtfläche markiert. Die Grenze, die diesen Flächenanteil von dem verbleibenden Flächenanteil unter der Kurve trennt, liegt in Abb. 29 bei etwa 1.66. Diesen Grenzwert bezeichnet man auch als kritischen t-Wert. Ein gleichgroßer oder größerer t-Wert tritt folglich nur in 5% der Fälle auf. Neben dem kritischen t-Wert wird ein empirischer t-Wert mit Hilfe der Ergebnisse aus der Stichprobe ermittelt.