Weitere relevante Kenngrößen
Hypothesen, Versuchsplan und Freiheitsgrade I
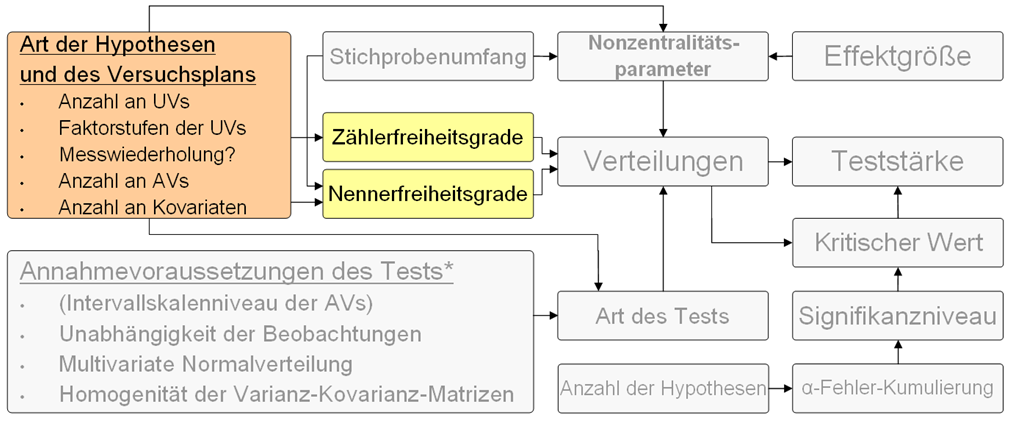
In diesem Unterabschnitt werden die Zähler- und Nennerfreiheitsgrade sowie die Art der Hypothesen und des Versuchsplans erörtert, welche die Teststärke einer Untersuchung maßgeblich beeinflussen. Unter Art der Hypothesen und des Versuchsplans werden folgende weitere Variablen subsumiert:
- Anzahl an unabhängigen Variablen
- Faktorstufen der unabhängigen Variablen
- Messwiederholung einzelner Variablen
- Anzahl an abhängigen Variablen
- Anzahl an Kovariaten
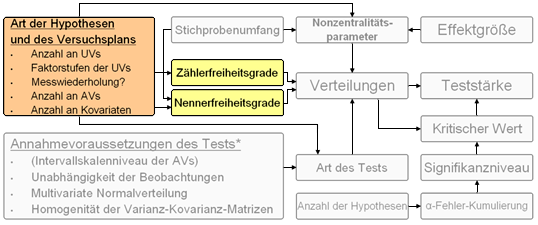
- Abbildung 42: Darstellung der Einflussfaktoren Zähler- und Nennerfreiheitsgrade sowie der Art der Hypothesen, welche die Teststärke der Untersuchung beeinflussen.
Definition
Die Zählerfreiheitsgrade geben die Anzahl der bei der Berechnung eines Kennwerts frei variierbaren Werte im Zähler an (im Englischen sowie bei GPower 3 als Numerator bezeichnet).
Synonym wird hier auch der Begriff Hypothesenfreiheitsgrade benutzt. Die Abkürzungen dfh, dfZ und dftreat (df ist die Abkürzung für degrees of freedom) beziehen sich allesamt auf diese Hypothesenfreiheitsgrade. Die Zählerfreiheitsgrade wirken sich maßgeblich auf die Teststärke eines Tests aus, da sie als Parameter die Kurvenverläufe der zentralen und nonzentralen Verteilung erheblich beeinflussen. Je größer die Zählerfreiheitsgrade, desto kleiner ist die Teststärke (bzw. desto mehr Versuchspersonen werden benötigt, um die gleiche Teststärke zu erzielen). Die Berechnung der Größe der Zählerfreiheitsgrade ist abhängig von der zu untersuchenden Hypothese, die wiederum angibt, welche abhängigen und unabhängigen Variablen (Faktoren) mit welchen Faktorstufen betroffen sind.
Komplexere Hypothesen
Stark vereinfacht kann man sagen, dass komplexere Hypothesen mehr Zählerfreiheitsgrade aufweisen und dadurch ein größerer Stichprobenumfang zu deren Überprüfung benötigt wird. Unter einer komplexeren Hypothese wird hier eine Hypothese verstanden, die sich auf zahlreiche unabhängige Variablen mit vielen Faktorstufen bezieht.
Berechnung im univariaten Fall
Die Formel zur Berechnung der Hypothesenfreiheitsgrade lautet im univariaten Fall (d.h. bei einer abhängigen Variablen):
Formel
dfh = (p - 1) ⋅ (q - 1) ⋅ ... ⋅ (z - 1)
Hierbei gilt:
p = Faktorstufen des ersten – für die Hypothese relevanten – Faktors
q = Faktorstufen des zweiten – für die Hypothese relevanten – Faktors
z = Faktorstufen des letzten – für die Hypothese relevanten – Faktors
Beispiele
Zwei Beispiele illustrieren die Berechnung der Hypothesenfreiheitsgrade:
- In einer Untersuchung wird der Haupteffekt einer fünffachgestuften unabhängigen Variable (p = 5) auf eine abhängige Variable überprüft. Die Zählerfreiheitsgrade betragen somit vier (5 - 1).
- In einer weiteren Studie werden die Zählerfreiheitsgrade für eine postulierte Wechselwirkung höherer Ordnung auf eine abhängige Variable ermittelt. Dabei kommen vier unabhängige Variablen zum Einsatz, die allesamt zweifachgestuft sind (p = 2, q = 2, r = 2, s = 2). Hier liegt nur ein einziger Zählerfreiheitsgrad vor. Dessen Berechnung lautet: (2 - 1) ⋅ (2 - 1) ⋅ (2 - 1) ⋅ (2 - 1) = 1.
Schlussfolgerungen
Aus der Formel zur Berechnung der Zählerfreiheitsgrade lassen sich folgende Schlussfolgerungen ziehen:
- Auswirkungen zweifachgestufter Variablen: Sind alle unabhängigen Variablen zweifachgestuft, können theoretisch beliebig viele unabhängige Variablen (Faktoren) vorhanden sein, ohne den Wert von einem einzigen Zählerfreiheitsgrad im univariaten Fall zu überschreiten. Für die Teststärke ist dies von großem Vorteil. Allerdings gilt dies nur für die Zählerfreiheitsgrade. Mit der Aufnahme weiterer (zweifachgestufter) Faktoren ändern sich die Nennerfreiheitsgrade (siehe unten) und damit die Teststärke.
- Auswirkungen n-fachgestufter Variablen: Bei vielen unabhängigen Variablen mit vielen Faktorstufen ergeben sich im univariaten Fall höhere Zählerfreiheitsgrade. Dies wirkt sich negativ auf die Teststärke aus bzw. es müssten – um dieselbe Teststärke zu erreichen – mehr Versuchspersonen erhoben werden.